
Coleção completa Classification Of Text Documents Using Sparse Features.
Classification of text documents. Text classification based on ensemble extreme learning machine feature extraction from text using python encontre classification of text documents using sparse features aqui.
Sklearn Feature Selection Chi2 Scikit Learn 0 23 1 Documentation
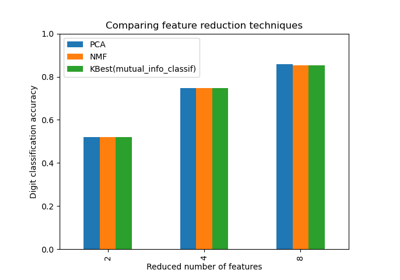
Feature Extraction
Http Www Jmlr Org Papers Volume2 Lodhi02a Lodhi02a Pdf
Recent Advances And Applications Of Machine Learning In Solid
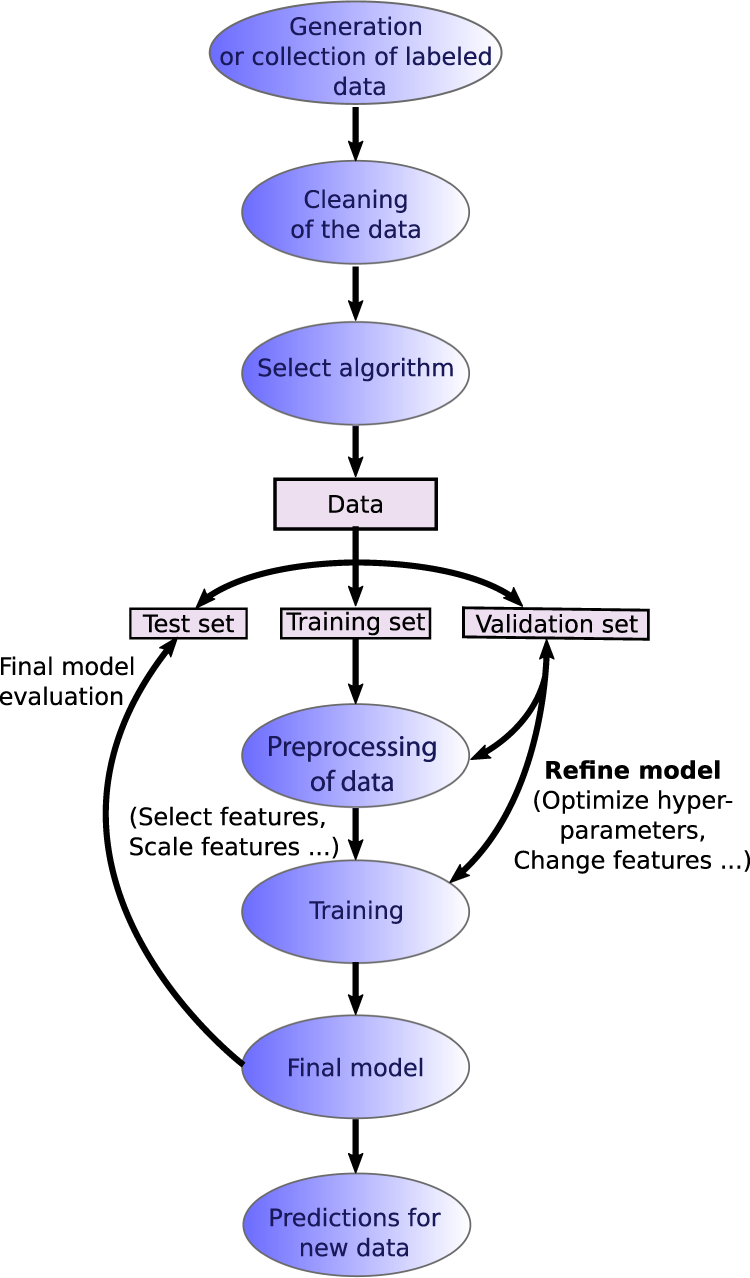
Create Simple Text Model For Classification Matlab Simulink

6 Topic Modeling Text Mining With R

This example uses a scipysparse matrix to store the features and demonstrates various classifiers that can efficiently handle sparse matrices.
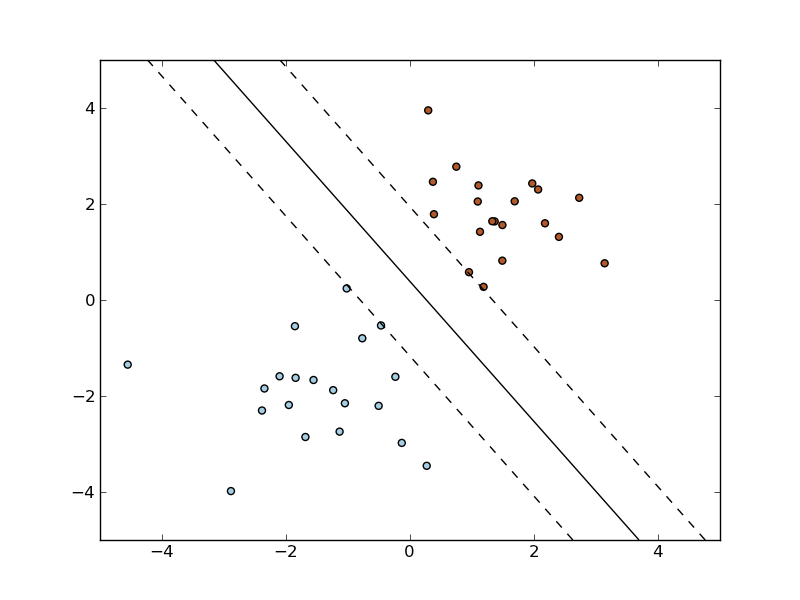
Classification of text documents using sparse features.
Using a mlcomp dataset this is an example showing how the scikit learn can be used to classify documents by topics using a bag of words approach.
Classification of text documents using sparse features this is an example showing how the scikit learn can be used to classify documents by topics using a bag of words approach.
This example uses a scipysparse matrix to store the features instead of standard numpy arrays.
Classification of text documents using sparse features this is an example showing how scikit learn can be used to classify documents by topics using a bag of words approach.
This example uses a scipysparse matrix to store the features and demonstrates various classifiers that can efficiently handle sparse matrices.
Tf idf are is a very interesting way to convert the textual representation of information into a vector space model vsm or into sparse features well discuss.
Sparsecg uses the conjugate gradient solver as found in scipysparselinalgcg.
This example uses a scipysparse matrix to store the features instead of standard numpy arrays and demos various classifiers that can efficiently handle sparse matrices.
Short introduction to vector space model vsm in information retrieval or text mining the term frequency inverse document frequency also called tf idf is a well know method to evaluate how important is a word in a document.
As an iterative algorithm this solver is more appropriate than cholesky for large scale data possibility to set tol and maxiter.
Classification of text documents using sparse features this is an example showing how scikit learn can be used to classify documents by topics using a bag of words approach.
Lsqr uses the dedicated regularized least squares routine scipysparselinalglsqr.
This example uses a scipysparse matrix to store the features instead of standard numpy arrays.
Classification of text documents using sparse features this is an example showing how scikit learn can be used to classify documents by topics using a bag of words approach.
This example uses a scipysparse matrix to store the features and demonstrates various classifiers that can efficiently handle sparse matrices.
Classification of text documents using sparse features this is an example showing how the scikit learn can be used to classify documents by topics using a bag of words approach.
É sobre isso que podemos compartilhar classification of text documents using sparse features. O administrador do blog de Texto Exemplo 09 January 2019 também coleta outras imagens relacionadas ao classification of text documents using sparse features abaixo.
Audio Classification For Information Retrieval Using Sparse

Improving Rare Disease Classification Using Imperfect Knowledge
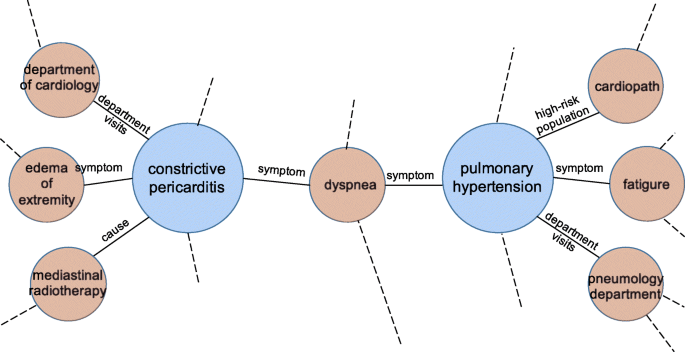
Introduction To Amazon Sagemaker Object2vec Aws Machine Learning
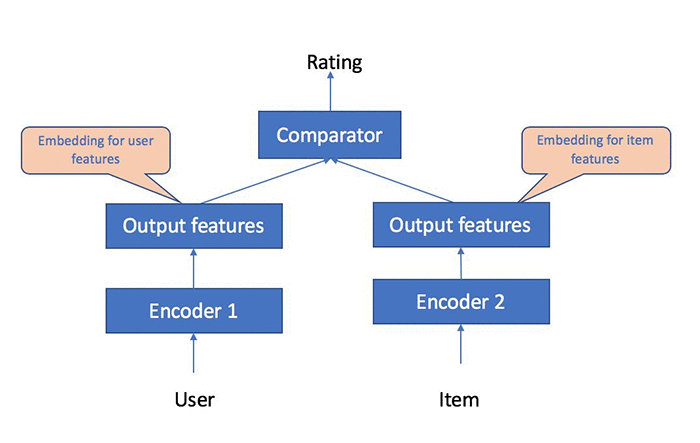
Https Arxiv Org Pdf 1904 08067
3 3 Stochastic Gradient Descent Scikits Learn 0 7 1 Documentation
Cosine Similarity Understanding The Math And How It Works With

Text Analysis And Classification Of Reviews In Python

Pdf Sparse Feature Selection For Classification And Prediction Of

Multi Class Text Classification With Scikit Learn Towards Data

Combining Sparse Coding And Time Domain Features For Heart Sound
Text Analysis 101 Document Classification
Essa é a informação que podemos descrever sobre classification of text documents using sparse features. Obrigado por visitar o blog Texto Exemplo 09 January 2019.